
To start this guide, download this zip file.
Split and join
In many tasks it is helpful to find all the words in a string. The split()
function does this by converting a string to a list of words. The join()
function goes in the opposite direction, converting a list of words into a
string.
Split
The default use of split() is to convert a string into words that are
separated by spaces:
question = 'Do you know the muffin man?'
print(question.split())This will print:
['Do', 'you', 'know', 'the', 'muffin', 'man?']By providing an argument to split(), called the delimiter, you can split a
string based on any character:
statement = "It is possible that I might, under other circumstances, have something to say, but right now I don't"
print(statement.split(','))This will print:
['It is possible that I might', ' under other circumstances', ' have something to say', " but right now I don't"]Here is a small program that uses split(), which you can find in cats.py:
def has_cat(text):
""" return true if the string has the word cat in it """
words = text.split()
return 'cat' in words
if __name__ == '__main__':
phrases = [
'I have a dog.',
'My cat eats bugs.',
'Can you concatenate two strings?'
]
for phrase in phrases:
print(phrase)
print(f'has_cat: {has_cat(phrase)}')
print(f'"cat" in: {"cat" in phrase}')
print()Take a close look at has_cat(). We (1) split the text into a set of words,
based on white space, and then (2) check if ‘cat’ is in those words.
Now take a look at the main block. We loop through all of the phrases and we print:
- the phrase
- whether ‘cat’ is one of the words (using
has_cat()) - whether ‘cat’ is contained in the string (without splitting into words)
If you run this program, it will print:
My cat eats bugs.
has_cat: True
"cat" in: True
Can you concatenate two strings?
has_cat: False
"cat" in: TrueNotice that has_cat() is False for the last phrase, because ‘cat’ is not one
of the words we get when we split the phrase, whereas ‘cat’ is in ‘concatenate’.
Join
Join takes a list of strings and joins them into a single string, using whichever delimiter you specify. Taking our first example, let’s put those words back together into a string:
words = ['Do', 'you', 'know', 'the', 'muffin', 'man?']
sentence = ' '.join(words)
print(sentence)This looks a little strange, but what we are saying is that we want to use a
space as a delimiter. This is the quotes with a space between them: ' '. We
can then call the join() function on this string, meaning take all the strings
in the words variable and turn them into one long string, with each word
separated by a space.
This will print:
Do you know the muffin man?We could instead use '-' as a delimiter:
words = ['Do', 'you', 'know', 'the', 'muffin', 'man?']
sentence = '-'.join(words)
print(sentence)and this will print:
Do-you-know-the-muffin-man?Similarly:
result = ' and '.join(['apples','oranges','bananas','pears'])
print(result)will print:
apples and oranges and bananas and pearsHere is a small program that uses both split() and join, which you can find
in cats_to_cougars.py:
def cats_to_cougars(line):
words = line.split()
new_words = []
for word in words:
if word == 'cat':
word = 'cougar'
new_words.append(word)
return ' '.join(new_words)
def main():
lines = ["BYU's mascot is cool, like a cat or something.",
"Just like a cat can, he can catch stuff."]
for line in lines:
print(cats_to_cougars(line))
if __name__ == '__main__':
main()
Take a close look at cats_to_cougars(), because it has a few core ideas:
split()the line into words- make a new list of words, so we can change ‘cat’ to ‘cougar’
join()that new list of words using space, so we can get back to a line- return that new line
To work with the words in a line, we have to change the line into words, manipulate the words, and then put the words back into a line.
Unemployment data
We are going to do some work with a file that contains unemployment data. This
file is in unemployment.txt and the top of the file looks like this:
State/Area Year Month %_Unemployed
Alabama 1976 1 6.6
Alaska 1976 1 7.1
Arizona 1976 1 10.2
Arkansas 1976 1 7.3
California 1976 1 9The columns are separated by tabs. The file contains data for many years! The bottom of the file looks like this:
Texas 2022 12 3.8
Utah 2022 12 2.4
Vermont 2022 12 3.0
Virginia 2022 12 3.1
Washington 2022 12 4.5
West-Virginia 2022 12 4.1
Wisconsin 2022 12 3.0
Wyoming 2022 12 3.9We want to write a program that finds the maximum unemployment for a given state, taken over all those years. This program takes two arguments:
- the input file
- the state
We have given you some starter code in unemployment.py:
import sys
def readlines(filename):
with open(filename) as file:
return file.readlines()
def main(input_file, state):
lines = readlines(input_file)
# write code here
# use additional functions
if __name__ == '__main__':
main(sys.argv[1], sys.argv[2])Planning
Work with a friend to design a solution for this problem. Can you develop a flow chart?

Here are two possible flow charts:
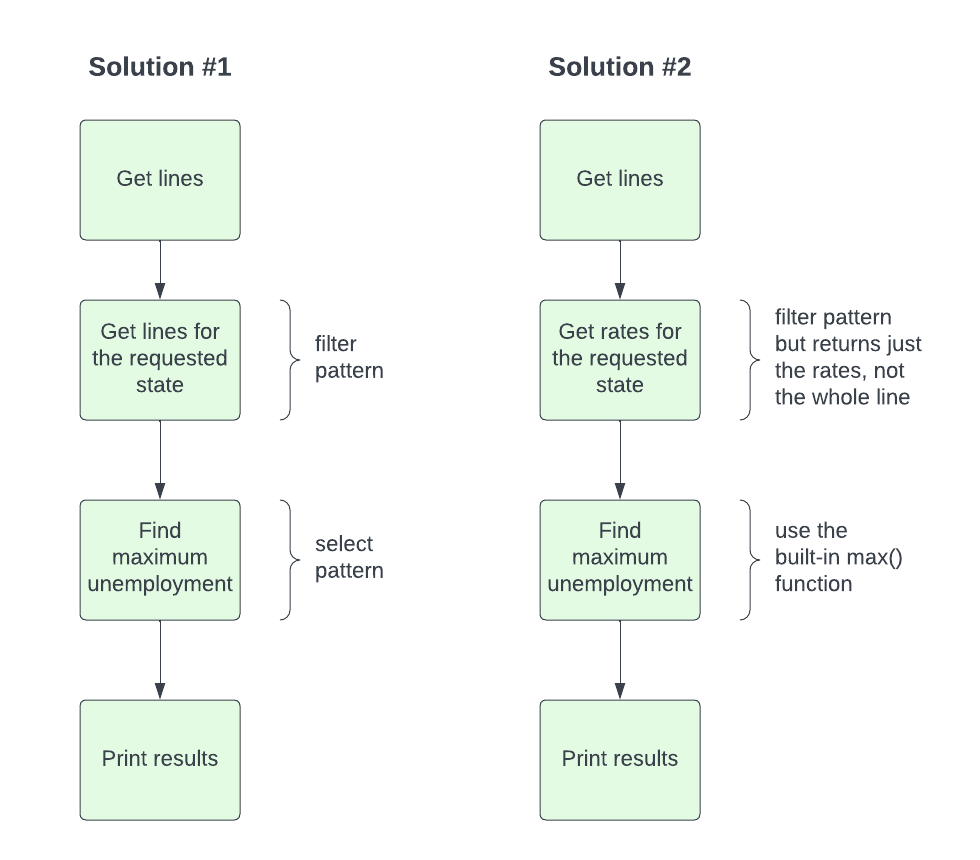
The solution on the left focuses on lines, so it first finds the relevant lines for the selected state, then goes through those lines to find the maximum unemployment rate.
The solution on the right is similar, but focuses on rates. So it first finds
the relevant rates for the selected state, returning them as a list, then it
uses the built-in max() function to get the maximum of those rates.
A word on splitting and indexing lines
Remember, lists can be indexed by integers. If we have a list:
names = ['Mariano', 'Anna', 'Salvadore', 'Lucia']Then the first name, Mariano, is at names[0] and the last name, Lucia, is at
names[3].
We also saw this with sys.argv, which is just a list of arguments given to the
program. So sys.argv[0] is the name of the program, sys.argv[1] is the first
argument, and so on.
If we have a line that we call split() on, then we can likewise use indexing
to get the “words” or “columns” in that line. So:
line = 'Alabama 1976 1 6.6'
info = line.split()
print(f"{line[0]} had {line[3]} percent unemployment in {line[1]} in month {line[2]})will print:
Alabama had 6.6 percent unemployment in 1976 in month 1Code for solution #1
Here is code that matches the flow chart on the left:
import sys
def readlines(filename):
with open(filename) as file:
return file.readlines()
def should_keep(line, state):
tokens = line.split()
return tokens[0] == state
def get_state_metrics(lines, state):
state_metrics = []
for line in lines:
if should_keep(line, state):
state_metrics.append(line)
return state_metrics
def find_max_unemployment(state_metrics):
max_ue = None
for line in state_metrics:
# % Unemployment is 4th token
record = line.split()
unemployment = float(record[3])
if max_ue is None or unemployment > max_ue:
max_ue = unemployment
return max_ue
def main(input_file, state):
lines = readlines(input_file)
state_metrics = get_state_metrics(lines, state)
max_unemp = find_max_unemployment(state_metrics)
print(f'The max unemployment for {state} between 1976 and 2022 was {max_unemp}')
if __name__ == '__main__':
main(sys.argv[1], sys.argv[2])
Read this code from the bottom up:
main()follows the flow chart: get the lines ➡️ get just the lines for a given state ➡️ get the maximum unemployment rateget_state_metrics()uses a filter pattern to get just the lines that are for the given stateshould_keep()uses the fact that the state is in the first column, which is index0in the list that is returned bysplit()find_max_unemploymentuses the select pattern to get the maximum rate; it uses the fourth column, which is index3in the list that is returned bysplit(); it also has to usefloat()to convert the number to a float
Code for solution #2
Here is code that matches the flow chart on the right:
import sys
def readlines(filename):
with open(filename) as file:
return file.readlines()
def get_state_rates(lines, state):
rates = []
for line in lines:
tokens = line.split()
if tokens[0] == state:
rates.append(float(tokens[3]))
return rates
def main(input_file, state):
lines = readlines(input_file)
ue_rates = get_state_rates(lines, state)
max_unemp = max(ue_rates)
print(f'The max unemployment for {state} between 1976 and 2022 was {max_unemp}')
if __name__ == '__main__':
main(sys.argv[1], sys.argv[2])
Read this code from the bottom up:
main()follows the flow chart: get the lines ➡️ get the rates for the state ➡️ find the maximum unemployment rateget_state_rates()uses the filter pattern, just likeget_state_metrics()above, but does it all in one function and returns a list of rates (converted to a float) instead of a list of lines- we can use the built-in
max()function to get the maximum of a list of floats
Is one of these approaches better?
Both of these are good solutions! The second solution takes advantage of the
built-in max() function so it uses a little less code. But the first solution
returns more information, so the maximum function could, for example, also
return the year and month for that maximum rate.
Ultimately, this is a judgement you make as a programmer to decide what you need, both to solve this problem and to provide flexibility for the future.

Photo by Damian Siodłak on Unsplash